
Context Engineering Is the Real Variable: Why Your Prompts Aren't the Problem
March 23, 2026
The Teams Winning With AI Didn't Write Better Prompts
The engineering teams shipping a million lines of code with three people are not using a different model than you. They are not writing cleverer prompts. They built a better environment for their agents to operate in.
The gap is not about capability. Every team has access to the same frontier models. It is about what you put in front of those models — how you structure the context, manage the memory, close the feedback loops, and give the agent a coherent picture of what it is supposed to do. Most teams are not doing that.
What Context Engineering Actually Is
In mid-2025, Andrej Karpathy gave the concept its clearest definition: context engineering is the delicate art and science of filling the context window with just the right information for the next step. Shopify CEO Tobi Lutke put it differently but got to the same place — it is "the art of providing all the context for the task to be plausibly solvable by the LLM." Both of them were reacting to the same observation: the conversation about prompts was missing the point.
Google's engineering team, building their Agent Development Kit, put it plainly in a February 2026 post: "context engineering — treating context as a first-class system with its own architecture, lifecycle, and constraints." That framing matters because it positions context as a system output, not a static string you paste into a chat box.
Context engineering is not a fancier version of prompt engineering. It is a different discipline entirely.
Most people think of context as a container. You put stuff in, the model reads it, you get a response. But that framing misses what is actually happening. The model has no memory outside the context window. Everything it knows about your task, your codebase, your preferences, your history, and your constraints has to live in that window right now. If it is not there, the model is guessing.
Here is what that looks like in practice. Two engineers hit the same model with tasks of equal complexity. Engineer A writes a clean, specific prompt. Engineer B writes a mediocre prompt but has a CLAUDE.md file in the repo root, a few relevant code examples loaded in, and a document that explains the team's conventions. Engineer B gets better output almost every time. The prompt barely mattered. The context did everything.
Why Context Failures Look Like Model Failures
One of the clearest patterns in the research on AI agent failures is that teams misattribute the root cause. When output is bad, the default response is to blame the model, swap models, or refine the prompt. The actual cause is almost always somewhere in the context.
Anthropic's engineering team made this case directly in their post on effective context engineering for AI agents: most agent failures are not model failures. They are context failures. The guidance across the different components of context — system prompts, tools, examples, message history — is to be thoughtful and keep context informative but tight. That is a design constraint, not a prompting problem.
Birgitta Böckeler at Thoughtworks, writing in February 2026, observed the same pattern from a practitioner angle: the number of options to configure and enrich a coding agent's context has exploded, and the teams getting reliable output are the ones treating that configuration work as real engineering rather than an afterthought.
The shift in mental model matters. If you believe the problem is the model, you keep swapping models. If you believe the problem is the context, you build a better context system. Only one of those compounds over time.
The Four Layers of Context
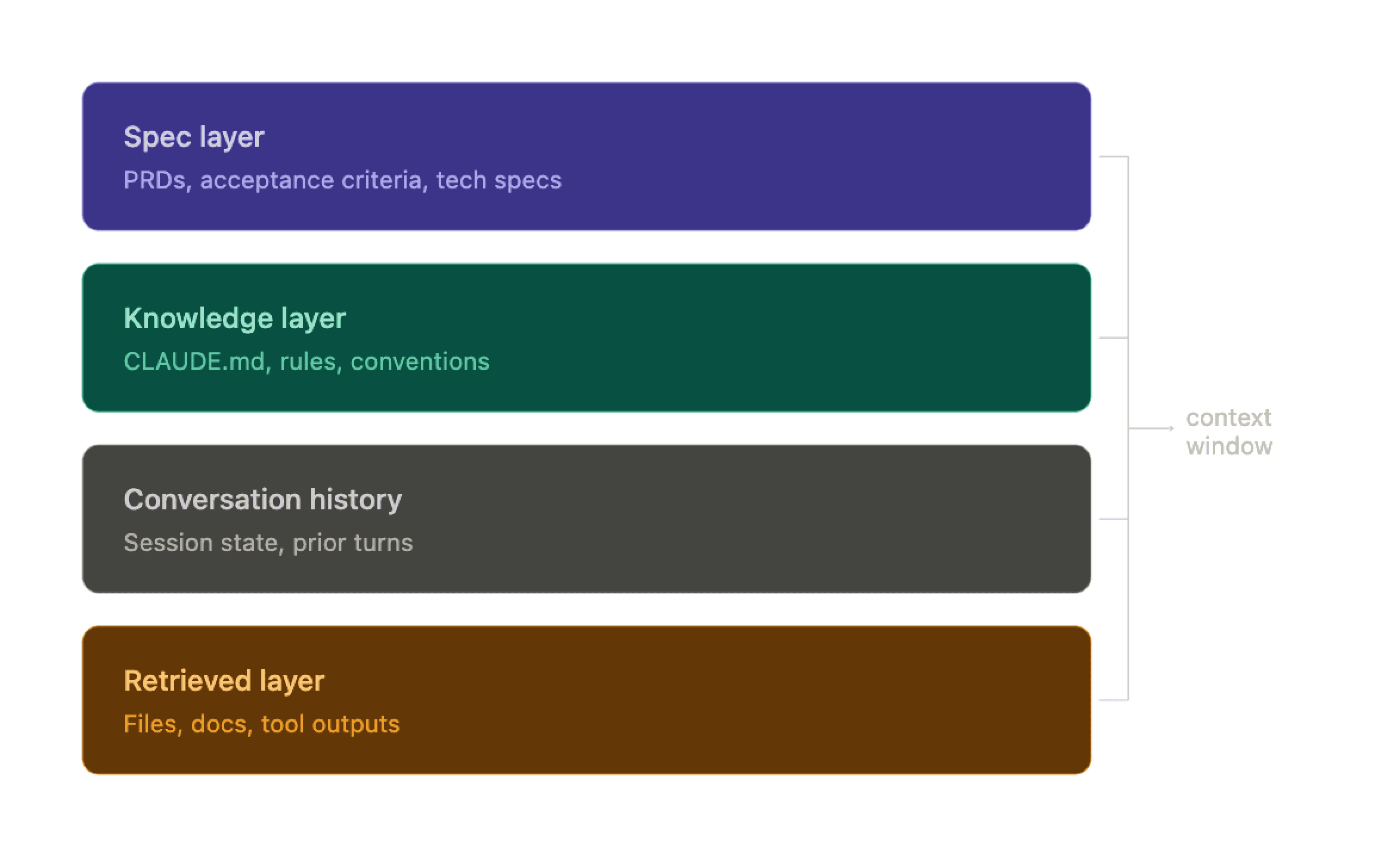
Context is not monolithic. It has distinct layers that serve different functions. Most teams are working with one or two of them. The teams getting reliable output at scale are working with all four.
Layer 1: The Spec Layer
This is the most underused layer in software development, and it is the one that most directly mirrors how good human engineering teams operate. Before a senior engineer writes a line of code, they read the PRD, the acceptance criteria, and the tech spec. The model should too.
A well-written PRD gives the model the "why" — what problem is being solved, who it is for, what success looks like. Acceptance criteria are more valuable still: explicit, testable statements of what done means. A tech spec translates that into implementation decisions — which services are involved, what the data model looks like, how the component fits into the broader architecture.
When teams skip this layer, the model fills the gap with its own assumptions. Sometimes those assumptions are fine. Often they are not, and you end up with output that is technically correct but wrong for your context.
Here is what a minimal but useful acceptance criteria block actually looks like:
Six lines of acceptance criteria. The model now knows what done looks like, what not to build, and one non-obvious edge case it would otherwise have to guess at. The out-of-scope section alone prevents a common class of scope creep that shows up in AI-generated code.
The spec layer also compounds. A living feature catalog — a record of what has been built, why it was built that way, and how it fits together — becomes one of the most valuable things you can put in front of a model. Without it, every new task starts from scratch. With it, the model understands the system it is working inside.
Layer 2: The Knowledge Layer
This is everything you inject to tell the model what it needs to know about your specific situation. In a coding context, this is usually a CLAUDE.md or similar file that lives in the repo root and gets loaded automatically. It contains architectural decisions, naming conventions, which libraries to use and which to avoid, and how the team handles common patterns.
The key insight is that this layer should read like documentation for a very smart new hire, not like a list of commands. You are not instructing the model on how to behave. You are giving it the background it needs to make good decisions on its own.
Compare these two approaches to the same task:
Same model. Completely different output. The difference is not the instruction, it's the context.
Here is what a real knowledge layer section looks like once a team has built it out:
That file lives in the repo root. Every session loads it automatically. The model never has to guess at naming conventions, never reaches for the wrong library, and never touches files it shouldn't. Write it once, update it as things change, and it pays off across every subsequent session.
Layer 3: Conversation History
This layer is often underestimated. The model reads everything that has come before in the conversation, and that history shapes every response it gives you. If your conversation history is full of vague requests, the model calibrates to that level.
Starting a new conversation for each distinct task keeps the context clean. Letting a single conversation run too long degrades quality because the model starts working with a cluttered, contradictory history. Long conversations also eat into your context window, which means the model may start dropping earlier content to fit newer content — often without any indication that this is happening.
Layer 4: The Retrieved Layer
This is anything you pull in dynamically based on the specific task — search results, relevant code files, documentation snippets, tool call outputs. The mistake most teams make here is retrieving too much. More context is not always better. Irrelevant context is actively harmful because it dilutes the signal and gives the model things to confuse with the actual task.
The discipline here is retrieval precision. You want the most relevant parts, not the most complete dump. A 200-line function that is directly relevant outperforms a 2,000-line file where 1,800 lines are noise. Teams that dump entire documentation sites into context and wonder why the model keeps mixing up unrelated features are making a retrieval problem, not a model problem.
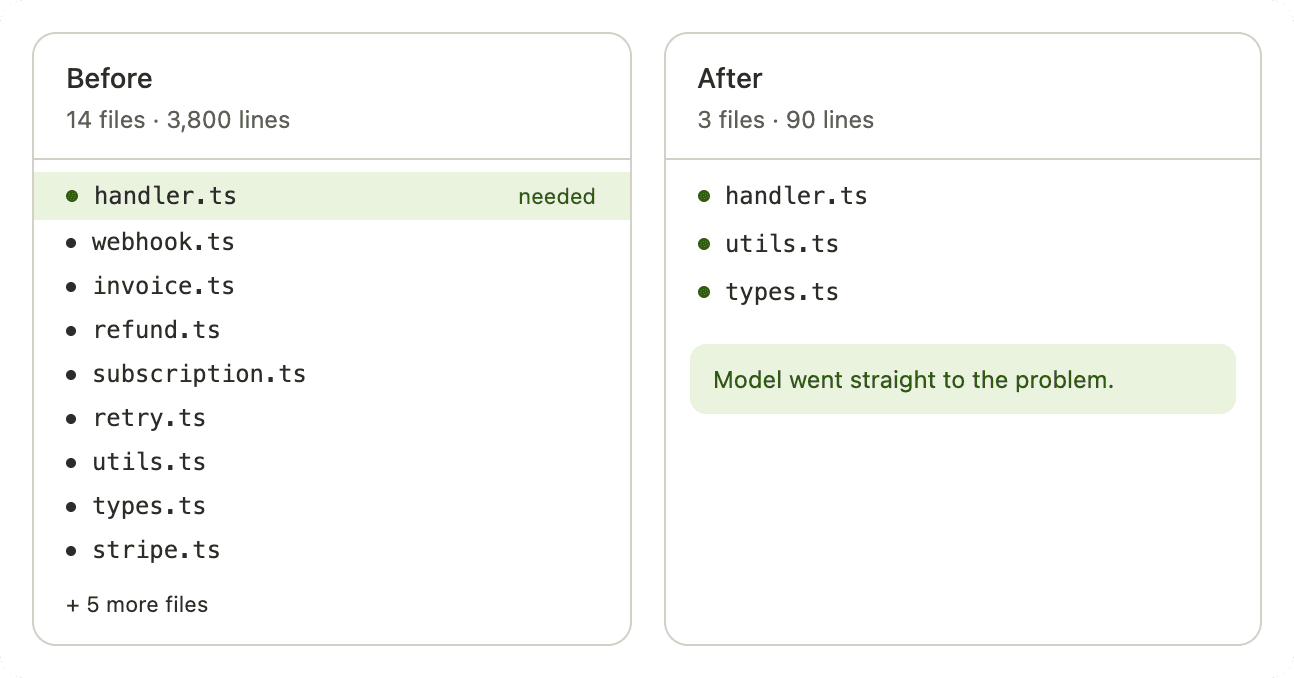
The before/after on this is stark. A team debugging a payment processing bug retrieves "everything related to payments" — 14 files, 3,800 lines, covering webhooks, invoicing, refunds, and subscription logic. The model has to reason across all of it to find the one function that matters. The same task with a precision pull: the specific handler, the two utility functions it calls, and the error type it's supposed to throw. 90 lines. The model goes straight to the problem.
More context is not always more signal. Past a certain point, it is noise — and noise has a real cost on output quality.
The Six Failure Modes That Repeat Across Teams
After working through this across different setups, the same failure modes come up repeatedly.
Skipping the spec layer entirely. Handing the model a vague task description and expecting it to infer intent is the single biggest source of bad output. A PRD does not have to be long. Even a one-page document with clear acceptance criteria changes the quality of the output dramatically.
Writing the knowledge layer in instruction style. The knowledge layer should read like documentation — background, context, conventions. The model processes that differently from a list of commands, and the output reflects it.
Not managing conversation length. Most people run one long conversation and wonder why quality drops off midway through a session. Fresh conversations for distinct tasks is not a workflow preference; it is a quality control measure.
Retrieval without curation. Pulling in every potentially relevant file is not the same as pulling in the right files.
Ignoring implicit structure. The order and format of what you put into context matters. Google's ADK team documented this in their February 2026 production analysis: context flooded with irrelevant data causes the model to fixate on past patterns rather than the immediate instruction. Putting your most important constraints at the end of your input consistently improves output.
Conflating model capability with context quality. When output is bad, most people blame the model. Most of the time, the problem is the context. Before concluding that a model cannot do something, rebuild the context from scratch and try again.
How to Build This in Four Weeks
If you are starting fresh, here is a week-by-week approach that actually works.
Week one: observe, don't optimize. Use the model normally but document every failure. What did you ask? What did it get wrong? What did it not know that it should have known? That list becomes the foundation of your knowledge layer.
Week two: build the knowledge layer. Take the failure patterns from week one and write a CLAUDE.md or equivalent that addresses them directly. Cover the things the model kept getting wrong because it did not know your domain: naming conventions, architectural constraints, library preferences, things that are off-limits. Write it like documentation, not instructions.
Week three: get serious about specs. Before starting any meaningful task, write at minimum a short PRD and a set of acceptance criteria. If the task is architecturally complex, add a tech spec. This does not have to be formal. A markdown file with a few sections is enough. The act of writing it forces clarity, and that clarity flows directly into better output.
Week four: test retrieval. If you are pulling in external content, start being deliberate about what you retrieve and how much. Run the same task with different retrieval strategies and compare output quality. You will usually find that less is more.
After that, it is iteration. The knowledge layer is a living document. Update it when you catch new failure patterns.
The whole thing takes about a month to get right. After that, you stop fighting the model and start working with it.
What This Has to Do With Specs
The spec layer is not incidental to context engineering. It is the most important layer.
This is the core insight behind spec-driven development: agents are only as good as their instructions, and the most important instructions are not the ones you type into a chat box. They are the ones you write before the session starts — the PRD, the acceptance criteria, the technical constraints, the architectural decisions.
When those documents live inside the repository, they are machine-readable. The agent can access them. When they live in a Slack thread or a Google Doc, they effectively do not exist from the agent's perspective.
The teams shipping reliably at scale are not treating specs as documentation for humans. They are treating them as the primary mechanism through which human intent becomes legible to agents. That framing changes how seriously you write them, how precisely you define done, and how consistently you maintain them as the codebase evolves.
The prompt is not the variable. The context is.
FAQ
What is context engineering? Context engineering is the practice of deliberately designing everything that flows into a model's context window — not just the prompt, but task descriptions, conversation history, retrieved documents, tool outputs, memory artifacts, specs, and the structure that ties them together. Andrej Karpathy defined it as the delicate art and science of filling the context window with just the right information for the next step.
How is context engineering different from prompt engineering? Prompt engineering focuses on crafting a single, well-worded instruction. Context engineering is a broader discipline concerned with the entire information environment the model operates in. A prompt lives inside a context. Context engineering is what determines what that context contains, how it is structured, and how it changes across a session.
Why does context quality matter more than model quality? Because every team has access to the same frontier models. The differentiator is not capability — it is environment. A model with poor context will produce poor output regardless of how capable it is. A model with rich, well-structured context will produce substantially better output, often from the same raw capability.
What is the most underused layer of context? The spec layer. Most teams skip it entirely and hand the model a vague task description. Even a short PRD with clear acceptance criteria dramatically changes output quality, because it eliminates the gap that the model would otherwise fill with its own assumptions.
What is context pollution? Context pollution is the presence of too much irrelevant, redundant, or conflicting information within the context window. It distracts the model and degrades reasoning accuracy. Teams often make the mistake of treating more context as better context. Retrieval precision — pulling in the most relevant information rather than the most complete dump — is one of the highest-leverage improvements available.
How do specs relate to context engineering? Specs are the primary mechanism through which human intent becomes legible to agents. In a well-designed context system, specs are not documentation for humans — they are machine-readable files in the repository that the agent reads to understand what to build, what counts as done, and what constraints to respect. Poor specs are one of the most common root causes of poor agent output.
Reference Articles
Effective Context Engineering for AI Agents — Anthropic Engineering, September 2025
Architecting Efficient Context-Aware Multi-Agent Framework for Production — Google Developers Blog, February 2026
Context Engineering for Coding Agents — Birgitta Böckeler, Thoughtworks / Martin Fowler, February 2026
Context Engineering for AI Agents in Open-Source Software — arXiv, revised February 2026
Context Engineering: Building the Knowledge Engine AI Agents Need — QCon London, March 2026
Andrej Karpathy on Context Engineering — X, June 2025
Related reading
The Harness Is Everything: Why Your AI Coding Agent Keeps Failing — Devplan
Spec-Driven Development — Devplan