
The Harness Is Everything: Why Your AI Coding Agent Keeps Failing
March 17, 2026
What Is an AI Agent Harness?
An AI agent harness is the complete designed environment in which a language model operates. It includes the tools the agent can call, how information is formatted and delivered into context, how history is compressed and managed across sessions, the guardrails that catch mistakes before they cascade, and the scaffolding that lets an agent hand off coherent work to its future self.
A harness is not a system prompt. It is not a wrapper around an API call. It is not a longer prompt or a better model. It is the infrastructure layer that determines what any model can actually accomplish, regardless of which model you use.
Ninad Pathak at Firecrawl published one of the most thorough breakdowns of the concept recently, covering the core components in detail: the tool layer, memory architecture, context compression, and verification loops. If you want a companion read that goes deep on component-level design, that is the one.
The distinction between harness and model matters because most teams spend their time optimizing the wrong thing. They iterate on prompts, swap models, adjust temperature. The teams shipping reliably at scale are investing in environment design.
Why AI Coding Agents Fail (And It Is Not the Model)
The pattern is consistent across every serious team that has documented this publicly. When an AI coding agent produces bad output, the root cause almost always traces back to one of four environment failures.
Context flooding. The agent receives too much information at once. Irrelevant data competes for attention with relevant data, and output quality degrades across every subsequent step.
Missing feedback loops. The agent writes code but cannot observe whether it actually works from a user's perspective. It optimizes for proxy metrics that do not reflect real correctness.
No persistent state. The agent has no reliable way to know what was done in a previous session, what counts as done, or what the current project state actually is.
Stale or informal context. Requirements, architectural decisions, and constraints live in Slack threads, Google Docs, or people's heads. From the agent's perspective, they do not exist.

Each of these is a harness problem, not a model problem. Kyle at HumanLayer makes this case with unusual directness in Skill Issue: Harness Engineering for Coding Agents. His argument, drawn from a year of watching coding agents fail in production: bad agent output is almost never a model problem. It is a configuration problem. Every failure is a signal about what the environment needs, and harness engineering is the discipline of treating it that way permanently rather than patching the prompt and moving on.
The Research That Proved It: The 64% Gap
The clearest empirical proof of this came from research that the harness engineering community keeps coming back to. Researchers tested the same model on identical coding tasks — real GitHub issues from popular open source repositories — using two different environments.
With a standard bash shell interface, the system resolved 3.97% of issues. With a purpose-built agent harness, the same model resolved 12.47%. That is a 64% relative performance improvement from environment design alone. Same model. Same task. Same compute.
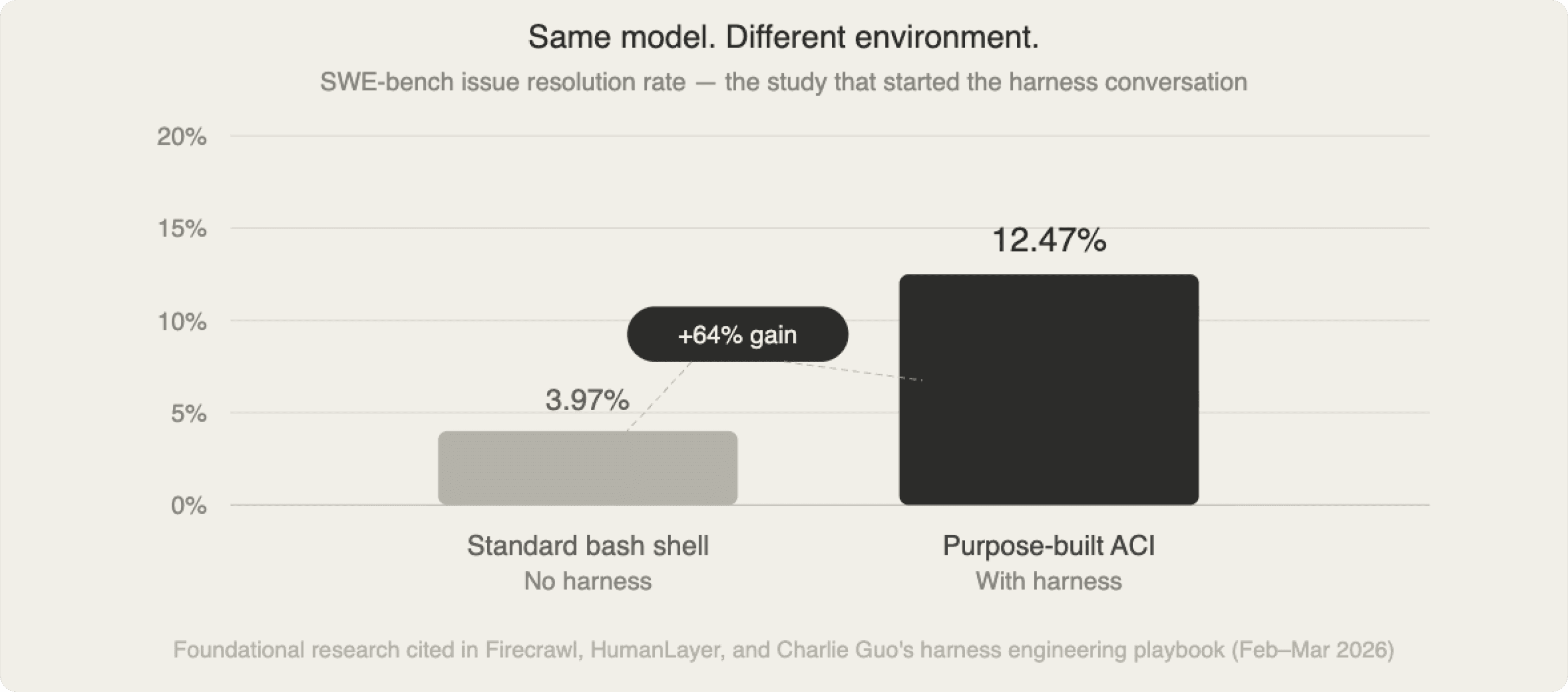
The harness achieved this through four specific decisions.
Capped search results. Standard search commands can return thousands of lines. When agents get flooded, they thrash, issuing more searches, accumulating noise, and filling context with irrelevant data. The harness capped results at 50 and forced refinement when exceeded. One design decision, one of the highest-leverage changes in the study.
A stateful file viewer with line numbers. The viewer maintained position across interactions and prepended explicit line numbers to every visible line. When an agent needs to edit specific lines, it should read those numbers directly rather than count them. Small cognitive load reduction, real compounding effect.
An editor with integrated linting. Every edit triggered an automatic linter. Syntax errors were caught and rejected before being applied, with a clear error message. Without this, agents introduce a syntax error, run tests, see a seemingly unrelated failure, and spend ten steps chasing a ghost.
Context compression. Older observations were collapsed into single-line summaries. The agent could always see recent, relevant state without being buried in the full uncompressed history of every command it had ever run.
The clearest proof in the literature that the bottleneck in AI agent performance is almost never the model. It is the environment.
How Anthropic Solved the Long-Running Agent Problem
Anthropic's engineering team, building Claude Code, encountered a harder version of the same problem: tasks too large to complete inside a single context window.
Most real software projects do not fit in any context window. A production web application has hundreds of files, thousands of functions, a test suite, configuration, and dependencies. Human engineers navigate this through external memory, documentation, and accumulated context built over time. An agent starting a fresh session has none of that.
Internal experiments revealed two failure patterns consistent enough to become the design spec for their harness architecture.
Attempting to do too much at once. Given a prompt like "build a clone of claude.ai," the agent would try to one-shot the entire application, implementing features without completing or testing any of them, running out of context mid-implementation, and leaving the next session to start with a half-built app and no documentation of what state it was in.
Declaring victory too early. After some features had been built, a subsequent agent would look around, see progress, and conclude the job was done. Not because it was unintelligent, but because it had no structured way to know what done actually meant for this project.
The Initializer and Coding Agent Architecture
The solution was a two-part harness. An initializer agent runs once and creates three things.
An init.sh script that reliably starts the development environment. Every subsequent session begins by running this script. The tokens saved on environment setup across dozens of sessions accumulate significantly.
A structured feature list — over 200 specific end-to-end feature descriptions, each initially marked as failing. This file is the project's ground truth. An agent starting a new session reads it and knows exactly what has and has not been built. It cannot look at working code and conclude the job is done. The feature list tells it the truth. Stored as JSON rather than Markdown deliberately — models are less likely to casually overwrite JSON files. The rigid structure resists the kind of editing you do not want.
A claude-progress.txt file updated at the end of every session. Combined with git history, it gives every future agent a fast orientation without burning context on archaeology.
The coding agent that runs in every subsequent session has a tighter mandate: work on one feature at a time, leave the environment clean, and update the progress file and git history before the session ends.

The Feedback Loop Failure Nobody Talks About
Anthropic also documented a failure mode that shows up in virtually every agentic coding project: agents marking features complete without verifying them end-to-end.
An agent writes code, runs a unit test, sees it pass, marks the feature done. But the feature does not work when a real user interacts with it through a browser. The gap between unit test success and real-world functionality is something human engineers navigate by actually running the application. An agent without browser automation cannot make that shift.
The fix was giving agents access to browser automation tools so the agent could navigate the application, click buttons, fill forms, and verify real user flows. The improvement was substantial.
The principle generalizes: the quality of an agent's work is bounded by the quality of its feedback loops. If the agent cannot observe the consequences of its actions in the domain that matters, it will optimize for proxies that do not correlate with correctness.
How OpenAI Shipped a Million Lines With No Manual Code
OpenAI's Codex team started a repository with one constraint: no human-written code. Everything including application logic, tests, CI configuration, documentation, and observability tooling would be written by agents. Humans would steer. Agents would execute.
The result: approximately one million lines of code, roughly 1,500 merged pull requests, and three engineers averaging 3.5 PRs per engineer per day. As the team grew, per-engineer throughput increased. A real internal product with hundreds of daily users.
The central observation from their writeup: the engineering job changed entirely. When you are not writing code, you are designing environments, specifying intent, and building feedback loops. When something failed, the fix was almost never "try harder." It was almost always "what structural piece of the environment is missing that is causing this failure?"
The Repository as System of Record
One of the most consequential decisions was making the repository the source of truth for everything an agent needed to know. Anything in a Slack thread or a Google Doc is invisible to the agent. If the agent cannot access it in context, it effectively does not exist.
Early on, the team tried the one big AGENTS.md approach, a single large instruction file containing everything. It failed in four consistent ways. A giant instruction file crowds out the actual task and relevant code. When everything is marked important, nothing is. A monolithic manual rots instantly as the codebase evolves. And a single blob is nearly impossible to verify for freshness or coverage.
The solution was a structured docs/ directory as the system of record, with a short AGENTS.md of roughly 100 lines serving as a map to deeper truth elsewhere. Progressive disclosure: agents start with a small, stable entry point and are pointed toward more when they need it, rather than overwhelmed upfront.
Mechanical Architecture Enforcement
When agents are opening 3.5 PRs per engineer per day, human code review cannot be the primary quality mechanism. The solution was encoding architectural constraints as mechanical checks that run at the point of violation rather than days later in a PR comment.
Custom linters enforced dependency directions, boundary crossing, and interface consistency. The key principle: enforce invariants, not implementations. Care deeply about structural rules. Do not dictate how a specific function is built, as long as it satisfies its behavioral contract. Every linter error message was formatted specifically for injection into agent context, including the rule violated, the violation found, and the remediation steps, all in one actionable message.
Where the Term "Harness Engineering" Came From
The term started spreading earlier this year. Charlie Guo's piece The Emerging "Harness Engineering" Playbook was the synthesis that circulated widely, drawing on converging practices from teams at OpenAI, Stripe, and others.
The core observation Guo made, and that the research supports, is that harness engineering is a discipline in the same way that infrastructure engineering is a discipline. It is not about any single tool or technique. It is about treating the agent's environment as a first-class engineering concern rather than an afterthought to the model.
The Five Patterns That Repeat Across Every High-Performing Harness
Across all of these systems and teams, several design patterns appear consistently. They are not coincidences. They are engineering solutions to problems that consistently emerge when deploying agents at scale.
Progressive disclosure. Give the agent the minimum it needs to orient itself, plus pointers to find more when it needs it. A short, focused entry point that maps to deeper context outperforms a comprehensive dump every time. It is also dramatically easier to keep accurate.
Git worktree isolation. One agent, one worktree. Every serious orchestration system uses this. Git worktrees give each agent its own working directory, branch, and environment. Changes are validated in isolation before touching the main codebase.
Spec first, repository as system of record. If it is not in the repository, it does not exist from the agent's perspective. Specifications, requirements, architectural decisions, and constraints must be encoded into machine-readable files before execution begins. Documentation is no longer just for human readers. It is the mechanism through which human intent becomes legible to agents.
Mechanical architecture enforcement. Encode architectural constraints as automated checks that run at the point of violation. Enforce invariants, not implementations. Allow significant freedom within them. The linter catches the violation and the error message remediates it. Human review focuses on judgment calls, not structural drift.
Integrated feedback loops. Close the gap between action and consequence as tightly as possible. Syntax errors caught at edit time. Runtime errors surfaced through observability tools the agent can query. UI bugs caught through browser automation the agent can drive. For agents, errors not caught immediately accumulate in context and degrade every subsequent reasoning step.
What This Means for How You Build
When something is not working in your agent system, the harness mindset produces a different diagnostic than the default one.
Instead of "how do I write a better prompt?" ask "what information does the agent need that it currently cannot access?"
Instead of "why is the model making this mistake?" ask "what feedback loop is missing that would catch this before it propagates?"
Instead of "why is the agent not doing what I told it?" ask "what constraint in the environment is preventing it?"
This shift changes where engineering effort goes. A prompt fix solves one specific failure mode. A harness improvement prevents a category of failure modes, permanently, across every future session.
The Minimal Harness for a Real Project
You do not need a full observability stack to benefit from this thinking. Four components cover most of it.
A persistent progress file. The agent reads it at session start and writes it at session end. This alone prevents the "declare victory too early" failure and ensures continuity across context window boundaries.
A structured task list with verifiable completion criteria. Not a vague project description. A specific, enumerated list of user-visible behaviors testable end-to-end. Status updates only after verification.
Version control as a first-class session requirement. Every session ends with a commit and an updated progress file. Clean state is not a nice-to-have.
Browser automation if you are building for the web. The difference between an agent that can only read code and one that can use the application it is building is the same as the difference between a developer who reads code and one who runs it.
The Uncomfortable Bottom Line
If execution is a commodity, and the evidence suggests it increasingly is, the long-term competitive advantage in AI-driven development is not the model. It is the harness.
The teams that have figured this out built custom development environments for their specific codebases and domains. They built harness architectures enabling months of coherent incremental progress. They demonstrated dramatically better results from the same models through environment design alone. None of those advantages came from the model. They came from the environment.
The model is what thinks. The harness is what it thinks about.
FAQ
What is an AI agent harness? An AI agent harness is the complete designed environment in which a language model operates, including its tools, context structure, memory management, feedback loops, and session scaffolding. It determines what the model can actually accomplish, independent of the model's raw capability.
Why do AI coding agents fail on complex projects? The most common failure modes are context flooding (too much irrelevant information degrading output quality), missing feedback loops (the agent cannot observe whether its work actually functions), no persistent state across sessions, and requirements that exist outside the repository where the agent cannot access them.
What is the difference between a harness and a prompt? A prompt is the input you send to the model in a single interaction. A harness is the entire system that determines what context the model receives, what tools it can use, how errors are caught, how state persists across sessions, and what constraints are enforced automatically. Prompts live inside harnesses.
How does spec-driven development relate to harness engineering? Specs are the primary mechanism through which human intent becomes legible to agents. In a well-designed harness, specs are not just documentation for humans. They are machine-readable files in the repository that the agent reads to understand what to build, what counts as done, and what constraints to respect. Poor specs are one of the most common root causes of poor agent output.
What is the minimal harness I can build today? Start with four things: a progress file the agent reads and writes each session, a structured feature list with verifiable completion criteria, git commits as a required end-of-session step, and browser automation if you are building a web product. That covers the majority of failure modes most teams run into.
Reference Articles
What Is an Agent Harness? The Infrastructure That Makes AI Agents Actually Work — Ninad Pathak, Firecrawl
Skill Issue: Harness Engineering for Coding Agents — Kyle, HumanLayer
The Emerging "Harness Engineering" Playbook — Charlie Guo, Artificial Ignorance
Foundational research
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering — Princeton NLP
Claude Code: Best Practices for Agentic Coding — Anthropic Engineering